Poem? I 'ardly know 'em!
Or: Using Machine Learning to Identify Poetic Comments
January 04, 2014Sometimes when reading the New York Times comments—between disgruntled complaints, armchair economics, and political banter—one stumbles across that rare gem, the comment poem:

But why should we have to sort through hundreds of regular comments and wait for a poem to catch our eyes? In this age of text mining, big data, and information extraction, shouldn’t a computer be able to do this for us? Well, whether or not this strikes you as a reasonable question to ask, the answer turns out to be yes! I wrote some code to do just that, and to find out how, read on…
First Steps
First we have to get the comments for analysis. Thanks to the NYT’s Times Developer Network API, this turns out to be pleasantly easy! With direct access to tens of thousands of comments, we can start to think about doing all kinds of interesting analysis, but today I’m just going to talk about finding poems. I chose to use Python for this task, because its overall flexibility and the availability of packages like numpy and scikit-learn makes an excellent tool for the kind of analysis I wanted to do.
It’s usually pretty easy (for a human) to tell if something is or isn’t a poem, but it’s difficult to quantify in a set of rules (this makes it a great task for machine learning, which I’ll talk about later on). I tried anyways though: for a simple first attempt, I just calculated the ratio of line breaks to other characters, on the theory that poems would have more line breaks than ordinary comments (most ordinary NYT comments contain one or a few relatively long lines, and few line breaks). This strategy turned up actual poems like this bizarre love note to Mark Bittman from our hero Larry Eisenberg:

But also strange rants like:

And long lists like:
The previous two comments are examples of false positives (comments that the rules indicate to be poems, but aren’t actually). There’s also a lot of false negatives (poems that aren’t detected by my rules). We’ll have to find a way to do better! But how?
Rhymes with Poem
Lots of poems employ a rhyming structure, whereas ordinary comments usually don’t. Rhymes can also be somewhat difficult for a computer to recognize, and accurately calculating rhymes and near-rhymes would require more sophisticated linguistic processing than I wanted to do for this project. But a quick rule of thumb that nevertheless catches a reasonably high percentage of rhymes is to compare the endings of two words and see how many characters they share (this is a very rough and simple rule, which could definitely be improved). For this program, I declare two words to rhyme if they end in the same two letters, and then count the percentage of rhyming words at the end of comment lines. To evaluate the performance, I categorized hundreds of comments as either poems or non-poems:

Sometimes it's hard to tell
With this simple rhyme detection included, the algorithm performs much better than the line break detection alone, but the performance is still limited. It’s easy to pick out Larry Eisenberg’s limericks, but non-rhyming verse slips through the cracks. Also some long comments show up as false positives because they have lots of line ending words, giving more chances for accidental “rhymes” (specifically, word-pairs grow as the square of the number of lines in the comment).
So far, we haven’t done any machine learning, or really anything at all sophisticated. And that’s about as far I went in a first-principles poem model building sort of way. Now it’s time to break out the machine learning toolbox!
Data Mining The Soul
The basic idea of teaching machines to learn has been around since Turing & co started thinking about computation. Today, machine learning refers to the practice of constructing systems that can learn from examples to make predictions on new, unseen data. Recently, with the increasing availability of all kinds of data and the computational power to process it, the field has exploded, with applications like self-driving cars, computer vision, and automated recommendations. In essentially any problem where a human could look at an example and make a decision about it, a computer can do it with a machine learning algorithm, enough data, and enough time. So poetry classification should fit right in (and indeed researchers have worked on similar problems).
{kind=link}
I manually classified thousands more comments so that I could start training a learning model. The model was trained on the following features: number of lines, average line length, standard deviation of line lengths (a measure of how uniform the lines are), and amount of rhyming. I also added features for two things I thought would be unlikely to show up in poems: number of numeric characters, and number of “special” characters (eg, $%#^*). These are all very simple to compute, and between them capture most of the structure of a comment, so the learning model should be able to figure out how to use these to classify poems.
Before training the model, we should have an idea of how to evaluate how well it’s doing. Because only something like one out of a thousand comments are poems, measuring prediction accuracy would be very misleading, since predicting that every comment is not a poem would be 99.9% accurate. So instead we use the F1 score, which ranges from 0 (poor) to 1(ideal) and penalizes for false positives and false negatives.
Scikit-learn has an excellent array of learning algorithms to choose from. I decided to use logistic regression, which is a simple and straightforward supervised learning classifier (though there are many other options, some of which I might explore later). Logistic regression also allows us to trade off between false positives (precision) and false negatives (recall), by adjusting the threshold of probability at which we declare a comment to be a poem. So we can set a low threshold to be confident of catching all the poems, at the cost of having a lot of false positives. Or we can have a high threshold to make sure that almost everything we flag is actually a poem, but we will miss a lot of other poems.
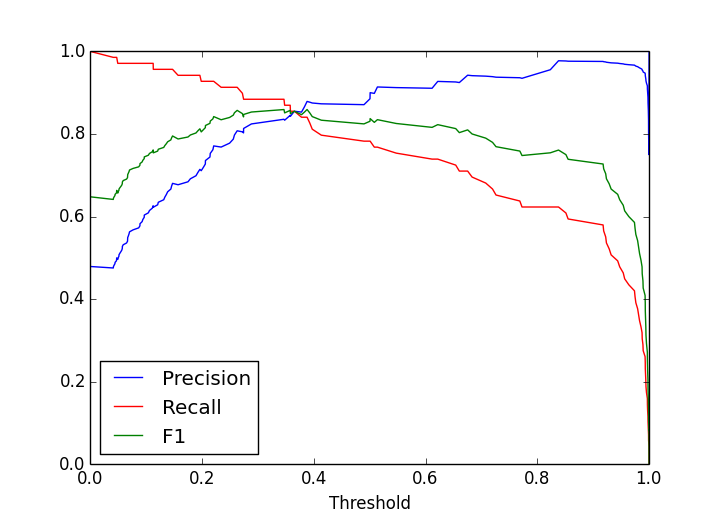
Precision-recall tradeoff and F1 score for the final trained model
Although this was a big improvement over the simple classification strategy described earlier, it still has a lot of false negatives and false positives, with an \(F_1\) score of about 0.5. One of the most interesting results of this model is that we can use it to get the relative importance of the different features of a poem:
Theta =
[ (-7.2096537078283305, ['aveLen']),
(-4.8577423788414134, ['stdev']),
(0.65553309239833091, ['rhymeQ']),
(0.41211121618657875, ['lines']),
(-0.39794436586003662, ["#'s"]),
(-0.25102236756414537, ['sChar'])]What this tells us is that poems are especially likely to have short lines compared to other comments, and also quite likely to have lines of relatively uniform length. Also, they are somewhat more likely to have lines that end in rhymes, and have more line breaks. Containing numeric characters and other special characters makes a comment less likely to be a poem as I suspected, but the learning model tell us that these aren’t very important features. Average line length and line length uniformity appear to be by far the two most important distinguishing features of a poem.
Scotty, We Need More Power(s)
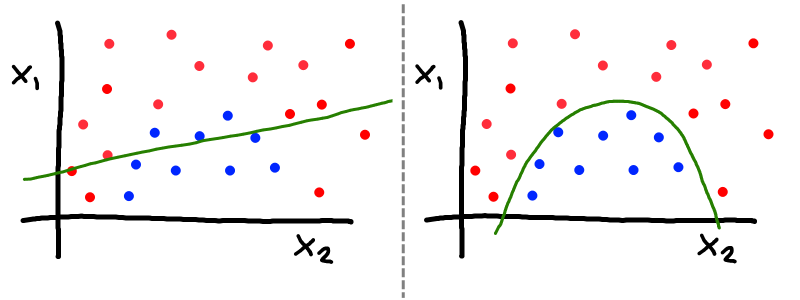
A two-parameter model with two categories separated by a linear boundary (left) and a nonlinear boundary (right).
Since logistic regression is a linear classifier, it can only make distinctions between poems and non-poems that look like straight lines (planes / hyperplanes) in parameter space. But in general, poems might not be linearly separable in the features we have chosen. For example, maybe comments with a moderate number of lines are likely to be poems, but comments with both very few and very many lines are not: there is no good way to pick a value and say comments longer than this are probably poems and comments shorter are probably not. To allow for more sophisticated learning, I generalize the model to make curved rather than straight boundaries. (Specifically, I used polynomial feature mapping to map the existing features onto arbitrary polynomial products of features. For practicality, I limit this to 3rd degree polynomials, as feature number grows exponentially with polynomial degree.)
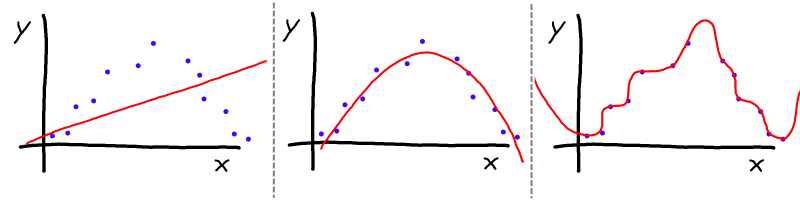
Diagram showing underfitting on the left and overfitting on the right. The center shows appropriate fitting. With the right amount of regularization, we can get a good fit despite having many parameters.
With additional features comes the problem of overfitting (aka high variance). With enough features, you can fit any data set with perfect accuracy, but the model would be meaningless: it wouldn’t generalize to comments it hasn’t seen. We can combat this using regularization. This penalizes the model for using large coefficients, so rather than trying to fit the data exactly, the model will try to produce a “smooth” prediction (with smoothness controlled by the size of the regularization coefficient), while still fitting the data approximately. Appropriately choosing the regularization coefficient will optimize the model’s ability to fit new data correctly.
This introduces one more problem: how can we choose the right regularization coefficient? The answer is to break the training data up into two sets, a training set and a test set. Now we can train the model with many different regularization coefficients, and choose the best one based on how the model performs on the test set.
The final model, trained on ~25,000 comments posted over a week, performs impressively well, identifying not just limericks, but also haikus, free-verse, and interesting “found poems” as well (see this post for more on the interesting poems of the week!).
Here There Be Details…
In the final model, the F1 score on the test set is about 0.83. As another point of reference, with a prediction threshold of 20%, the model is expected to miss about 5% of comments that could be classified as poetry, and incorrectly identify about 30% of responses as false positives (at a 50% threshold, we would miss 20% of poems, but only incorrectly identify about 10%). The parameters for the final trained model are:
Theta =
[ (-4.4286398462753569, ['stdev', 'INV_aveLen']),
(-2.6152500876025178, ['INV_aveLen', 'INV_aveLen']),
(-2.1601108718169186, ['INV_lines', 'INV_aveLen']),
(-1.5661835626301197, ['aveLen', 'INV_aveLen']),
(-1.4763161231121018, ['INV_lines', 'INV_rhymeQ']),
(1.4050428584597547, ['INV_aveLen']),
(1.2017039641098926, ['lines']),
(0.81023821647484218, ['rhymeQ']),
(-0.78775350480991047, ["#'s", 'INV_sChar']),
(-0.76201605500088798, ['lines', 'lines']),
(-0.76028261886262782, ['lines', 'aveLen']),
(0.63474128816594866, ['INV_aveLen', 'INV_sChar']),
(-0.59726188490530607, ['aveLen', 'rhymeQ']),
(0.54676271186435077, ['lines', 'rhymeQ']),
(0.50811316869729972, ['lines', 'stdev']),
(-0.36339272447523757, ["#'s", 'INV_aveLen']),
(0.28263804343744037, ['lines', 'INV_rhymeQ']),
(-0.21376816680099142, ['rhymeQ', 'rhymeQ']),
(-0.18725536650062383, ['lines', "INV_#'s"]),
(-0.18436001068148844, ['rhymeQ', 'INV_lines']),
(0.097228828727091557, ['rhymeQ', 'INV_sChar']),
(0.082100023517069104, ['rhymeQ', "INV_#'s"]),
(0.074220229682818925, ['INV_aveLen', 'INV_rhymeQ']),
(-0.070214398383472529, ["#'s", "INV_#'s"]),
(-0.03687714292671937, ['rhymeQ', 'INV_stdev']),
(0.022787901290648147, ["INV_#'s", "INV_#'s"]),
(-0.0091864125942432914, ['lines', 'INV_sChar']),
...All the remaining parameters are set to zero, a property of l1 regularization, which tends to produce sparse models. This model includes inverse features (defined as \(1/X\) for each original feature \(X\)), and degree 2 polynomial products of features. The most significant feature in the final model is \(\sigma_L/\mu_L\), which interestingly is the coefficient of variation of line length (where \(\mu_L\), is the average line length, \(\sigma_L\) is the standard deviation of line length). Comments with a high coefficient of variation turn out to be especially unlikely to be poems. The second most significant is \(1/\mu_L^2\), which penalizes comments with both very short and very long line lengths. Third is \(1/(\textrm{Lines}*\mu_L)\), which is the number of characters in a comment: posts with small numbers of characters are not likely to be poems (the benefit of using the inverse here is that it strongly penalizes posts with very few characters, but makes little distinction between posts with moderate and large character counts). Somewhat puzzling is the next feature, \(\mu_L/\mu_L\), which at first glance appears to be just a constant, but because of the way the code computes the inverse and then scales features to be of uniform mean and standard deviation, this is an “accidental” feature that penalizes only comments with very short lines. Together with other features, this is selecting for average line length in a complicated, nonlinear way, which is exactly what we were looking for this model to do!
For the brave, visit my GitHub page to try the code out for yourself!